我不只一次看過這樣的說法:「Prompt愈短愈好。」
然而,我常常把背景資訊交代完,就超過兩行了。
(不知道是不是跟歷史系出身有關係,我講一件事情的時候都希望可以把一個脈絡講清楚🤔)

這讓我很掙扎,我也希望問題愈簡潔愈好,但總是做不到。於是,我開始去懷疑問題真的是愈短愈好嗎?輸入的Prompt字數愈少,得到ChatGPT的回覆會愈精確、愈完整嗎?
.
.
.
你可能曾經看過類似的貼文、快訊,XX模型的token數放寬了,好像是件大事一樣。

.
首先,我們必須要先知道大型語言模型都會有一個最大token數量的限制。在NLP(自然語言處理)中,Token是文字被分割的最小單位。這個單位可以是一個字、一個詞,甚至是一個句子,token的長度或定義取決於處理的上下文和特定任務需求。
那我們是怎麼判斷這個token要怎麼組成呢? 我們請到ChatGPT來說明一下:
一種常用的 Token 分割方式是使用 "Byte Pair Encoding"(BPE)算法。這種方法會找出最常出現的字符組合,並將它們合併成新的 Token。這樣不僅可以適應不同語言的特點,也能有效處理生僻詞或拼寫錯誤。
假設我們正在處理英文文本,NLP會將「I love you」這個句子拆成三個token,變成「I」、「love」、「you」。(備註:BPE並不是專門為中文設計的。而且中文不像英文,會以空個來區分詞彙,因此中文的詞元分割變得更複雜。但在這裡這個議題有點扯太遠,所以我們不再細說。)

.
.
因此,當輸入的問題愈冗長,token數也會變長。為了防止過長的資訊量影響到大型語言模型的表現能力,因此絕大多數的模型在對外開放的時候,都會有「token數的上限」,像GPT3的token限制就是4096。
當你輸入過長的資訊,超出模型設定的限制時,通常會跳Error。
但不只是這樣,大型語言模型回覆你的token數加上你輸入的token數,也有一個「問+答」的總合限制。因此,當你輸入的資訊過長,以至於壓縮到它回覆你可以使用的到token數的時候,你就會拿到一個比較沒那麼完整、沒那麼精確的答案

.
.
.
了解token數之後,我們再來看問題是否愈短愈好這個問題,你就會發現:這其實不一定。
當我的是一個小問題,或是複雜度不高的問題時,大型語言模型就不需要使用太多的token數來回覆。也就是說,我只要能將「問+答」的token數控制在一定範圍,在這個範圍內去輸入一個長問題並不會影響到回覆品質。
相反的,當輸入的資訊量過長的時候,就要留意他回覆的品質是否下降。
我自己最近常碰到的例子是,我的鐵人賽文章在完成草稿後,我會把整篇文章都到ChatGPT請他幫我潤稿,或是給我一些優化的建議。當我輸入的文章過長時,就只會得到像這樣比較攏統的建議(請見下圖)。
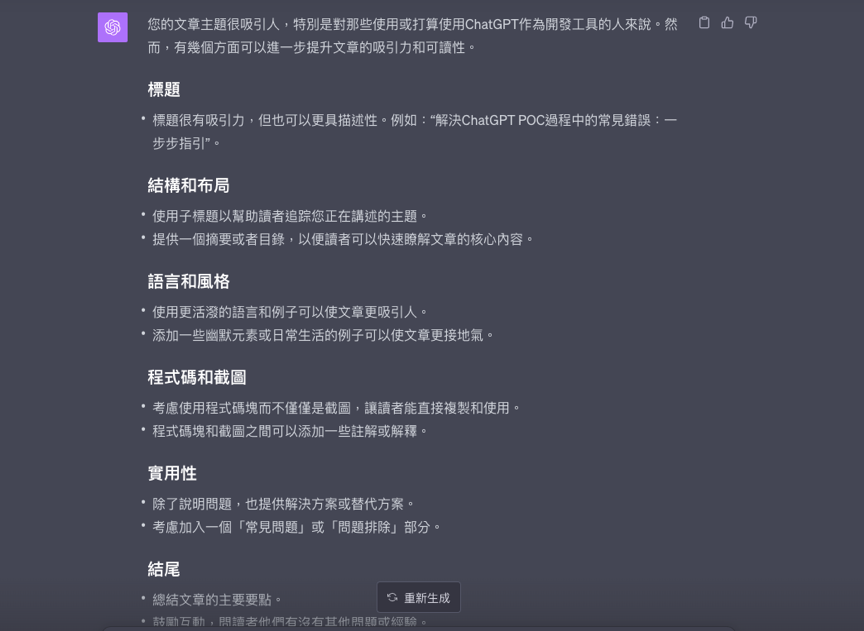
這種建議就是「聽君一席話,如聽一席話」的廢話,隨便貼一篇文章也可以適用同樣的建議。即使我另開了視窗重貼一次後,也是得到差不多的結果。這時候我就會提醒自己有可能是輸入的指令太長,而造成的影響。
.
.
.
現在我們知道只要將「輸入+輸出」的token數控制在一定範圍內,就不必鑽牛角尖是不是要把自己的問題弄的愈短愈好。不過我們仍要注意,當我們的問題愈長的時候,往往會夾雜一些非必要資訊進而讓問題失焦。這就不是一個「好問題」了。
所以,問題的長度是「偽議題」,重點還是你是否清楚、具體的表達了你的問題/需求/目標,以及你是否提供必要的背景資訊。
.
.
.
希望今天過後,大家不會再被「要寫一個簡短的問題」給困擾住😎
明天,我們會提供一些具體提升Prompt準確度的tips,希望大家準時收看:)


 iThome鐵人賽
iThome鐵人賽